
이번 주 기술 뉴스의 핵심은 AI 성능 경쟁처럼 보였지만, 실제 흐름은 데이터가 어디까지 움직일 수 있는가에 가까웠습니다. 기업, 투자, 산업, 미국, 글로벌 경쟁을 가르는 기준도 모델 자체보다 접근권과 책임 구조로 이동하고 있습니다.
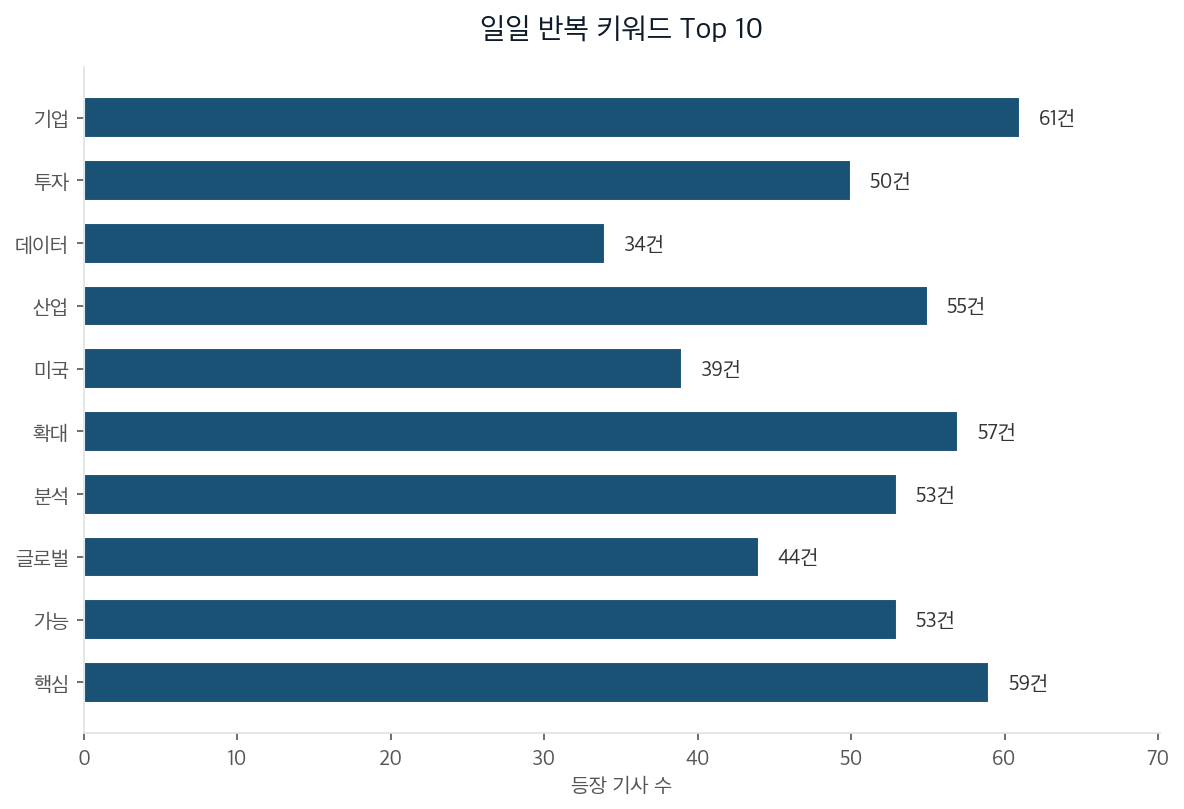
이번 일일 뉴스에서 가장 많이 등장한 키워드 Top 10입니다.

의료 AI 뉴스는 겉보기엔 더 좋은 알고리즘을 만드는 경쟁 같지만 실은 데이터 이동권을 둘러싼 산업 재편이었습니다.
한국은 단일 건강보험 체계, 높은 전자의무기록 보급률, 병원 인프라, ICT 환경을 갖추고 있습니다. 조건만 놓고 보면 의료 AI 기업이 성장하기 좋은 나라입니다. 그런데 현장에서는 병원 설득, 연구윤리심의, 가명 처리, 반출 심사, 표준화, 품질 관리가 계속 병목으로 남습니다.
여기서 중요한 말은 “부족”이 아닙니다. 데이터가 없어서 못 쓰는 구조가 아니라, 있어도 움직이기 어려운 구조입니다.
오늘 반복 키워드에서도 기업은 61개 기사, 산업은 55개 기사, 투자도 50개 기사에 등장했습니다. 하루 뉴스 묶음에서 세 단어가 동시에 높게 나온다는 것은 기술 소개보다 사업화 조건을 묻는 기사가 많았다는 뜻입니다. 숫자로 보면 기업과 산업은 각각 50개를 넘었습니다. 한두 기업의 신제품 보도라기보다, 시장 전체가 같은 병목을 바라보기 시작했다는 신호입니다.
데이터는 겉보기엔 많이 쌓을수록 유리한 자원 같지만 실은 누가 접근하고 결합하며 결과에 책임지는지가 가격을 정하는 자산이었습니다.
의료 기록은 병원 안에 있을 때는 진료의 흔적입니다. 그런데 복약 관리, 질환 모니터링, 임상, 보험, 신약개발, 병원 운영 자동화와 연결되면 산업의 재료가 됩니다. 문제는 그 연결이 합법적으로 반복 가능해야 한다는 점입니다.
모델은 한 번 개선되면 복제 속도가 빠릅니다. 반대로 데이터 파이프라인은 병원마다 절차가 다르고, 심의 기준이 다르며, 책임 소재가 다릅니다. 이 차이가 의료 AI 기업의 속도를 가릅니다.

데이터 산업은 겉보기엔 많이 가진 기업의 게임 같지만 실은 정리해서 반복 판매 가능한 구조를 만든 기업의 게임이었습니다.
금융 시장도 비슷했습니다. 과거에는 공시 자료와 리포트에 먼저 접근하는 쪽이 유리했습니다. 시간이 지나며 단말, 퀀트 분석, 대체 정보, 실시간 가격 정보가 결합됐습니다. 우위는 정보 보유에서 처리 속도와 해석 체계로 이동했습니다.
의료도 같은 방향으로 갑니다. 다만 속도는 더 느립니다. 오판 비용이 크고, 환자 정보는 민감하며, 책임 소재가 복잡하기 때문입니다. 그래서 의료 데이터 시장은 기술보다 제도 정렬이 앞에 놓입니다.
미국과 글로벌 시장을 보는 이유도 여기에 있습니다. AI 모델 경쟁은 국경을 빠르게 넘지만, 의료 정보의 이동 규칙은 국가별로 다르게 작동합니다. 같은 기술을 가진 기업이라도 어느 시장에서 어떤 절차로 데이터를 만질 수 있는지에 따라 사업 속도가 달라집니다.
데이터 플랫폼은 겉보기엔 정보를 모아 보여주는 화면 같지만 실은 투자와 운영 판단을 줄이는 절차였습니다.
분석본에 나온 40만 개 빌딩 데이터와 250만 개 기업 데이터는 단순한 목록이 아닙니다. 40만 개는 사람이 건물 하나씩 확인하는 방식으로는 감당하기 어려운 규모입니다. 250만 개 기업 정보까지 겹치면, 어느 건물에 어떤 업종이 들어가고 빠지는지까지 판단 재료가 됩니다.
의료에서도 같은 전환이 가능합니다. 진료기록 하나는 개인의 기록입니다. 여러 기관의 표준, 동의, 보안, 심의가 맞물리면 제품 개발과 환자 관리의 입력값이 됩니다. 그래서 핵심은 “더 많이 모으기”가 아니라 “같은 규칙으로 다시 쓸 수 있게 만들기”입니다.
이 구간에서 기업은 모델보다 계약, 보안, 표준화, 감사 체계를 먼저 증명해야 합니다. 투자자는 기술 설명서보다 데이터가 실제 제품으로 이어지는 절차를 확인해야 합니다.

의료 AI 확대는 겉보기엔 스타트업의 알고리즘 기회 같지만 실은 병원 네트워크와 법무·보안 체계를 갖춘 기업의 초기 우위였습니다.
시나리오를 나누면 특별법과 표준화가 진행되며 시장이 열릴 가능성이 45%로 제시됐습니다. 이 경우 수혜는 좋은 모델을 가진 기업에만 가지 않습니다. 합법적으로 반복 가능한 데이터 파이프라인을 가진 기업이 먼저 앞섭니다.
법은 생기지만 현장 절차가 무거운 경우도 40%입니다. 이때는 시장이 열려도 속도가 제한됩니다. 대형 병원, 대기업, 공공 과제 중심으로 사업이 움직일 가능성이 큽니다. 병원 업무 자동화, 문서 처리, 비식별 처리, 표준화 솔루션처럼 병목을 줄이는 기업이 더 현실적인 후보가 됩니다.
개인정보 사고가 터져 규제가 다시 강해지는 경우는 15%입니다. 15%는 낮아 보이지만, 여섯 번 중 한 번에 가까운 확률입니다. 한 번의 사고가 시장 속도와 기업가치 평가를 동시에 낮출 수 있다는 뜻입니다.
이 결론은 데이터 사용 시장이 결국 확대된다는 가정을 품고 있습니다. 그러나 의료에서는 사회적 신뢰 비용이 예상보다 클 수 있습니다. 환자 동의, 사망자 정보, 건강관리와 의료행위의 경계 같은 쟁점에서 합의가 늦어질 가능성이 있습니다.
데이터는 겉보기엔 산업 성장의 연료 같지만 실은 신뢰와 책임이 정렬될 때만 움직이는 자산이었습니다.
그래서 7월 1일의 핵심 신호는 AI가 의료를 바꾼다는 구호가 아닙니다. 데이터가 많은 나라에서 데이터가 실제로 흐르려면, 기술보다 먼저 접근권, 표준, 보안, 책임 배분이 맞아야 한다는 점입니다. 기업과 투자자는 모델 성능보다 이 구조를 먼저 봐야 합니다.